We present a subject specific human conversational interaction classification using 3-D pose features. We adopt Kinect sensors to obtain 3-D displacement and velocity measurements, followed by wavelet decomposition to extract low level temporal features. These features are then generalized to form a visual vocabulary that can be further generalized to a set of topics from temporal distributions of visual vocabulary. A subject specific supervised learning approach based on Random Forests is used to classify the testing sequences to seven different conversational scenarios. The difference among the seven scenarios are rather subtle, and the primitive actions and interactions are commonly exhibited across different scenarios. Experiments are conducted on 869,142 frames, completed by 8 different pairs of people in 482 min, and the results suggest that it is indeed feasible to understand human conversational activity based on the gesture cues alone.
Data acquisition
We choose seven conversational categories and use a two-Kinect set-up to record 3-D human pose. Each person is recorded using a Kinect Sensor, which captures human pose at 30 fps. Each of the cameras is slightly offset from a direct frontal view so that the participants do not occlude one another. The participants are given seven conversational tasks to complete.
 |
| The seven tasks given to the participants to perform. |
| Describing Work |  |
| Story Telling |  |
| Problem Solving |  |
| Debate |  |
| Discussion |  |
| Subjective Question |  |
| Telling Jokes |  |
| | Example images and their 3D skeletons of the seven scenarios. |
Proposed method
The displacement and velocity measurements are first extracted from the Kinect output. Wavelet decomposition is then applied to extract low level features from each of those measurements. The wavelet coefficients represent sudden changes in measurements at different temporal scales, and they are treated as the low level motion features. A temporal generalization of those features are then carried out to encapsulate temporal dynamics, which first produces a visual vocabulary and then further generalized them to visual topics through Latent Dirichet Allocation analysis. A discriminative model based on Random Forests is then trained and applied to classify different types of conversational interactions in a subject specific fashion.
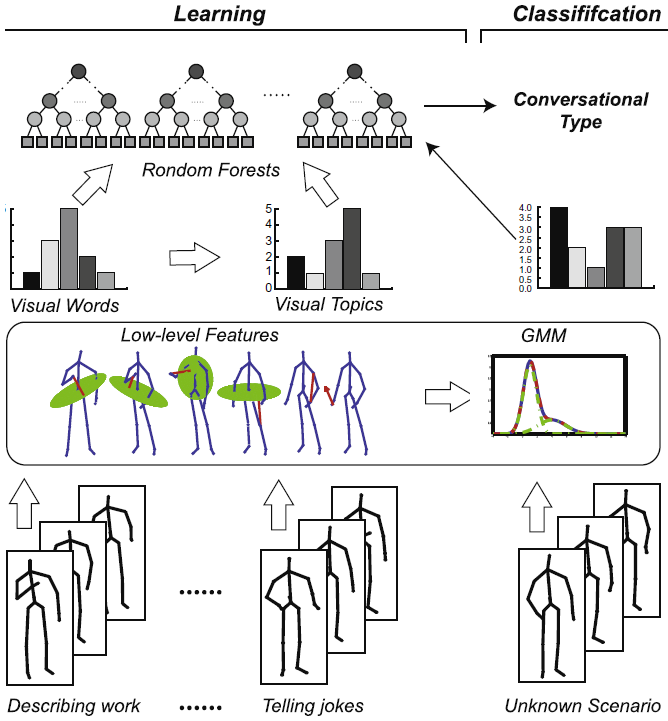 |
| The flowchart of the proposed method. |
Example results - pose features from a single person
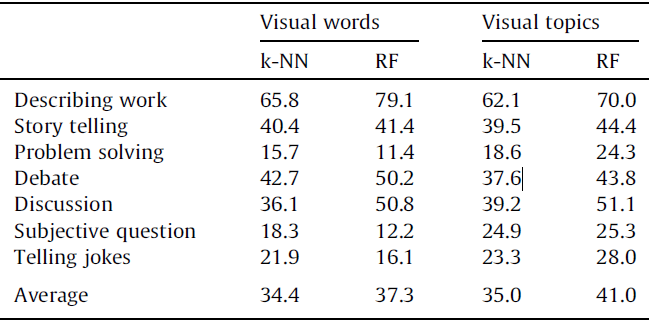 |
| The average classification results using visual features from only a single participant (K = 5 for K-NN). |
Example results - pose features from paired persons
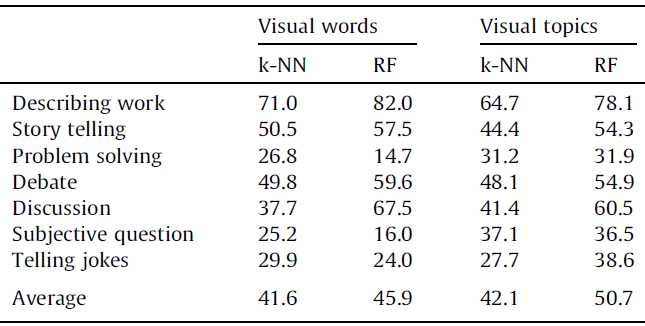 |
| The average classification results using visual features from paired participants (K = 5 for K-NN). |
Example results - Random Forests classification using visual words
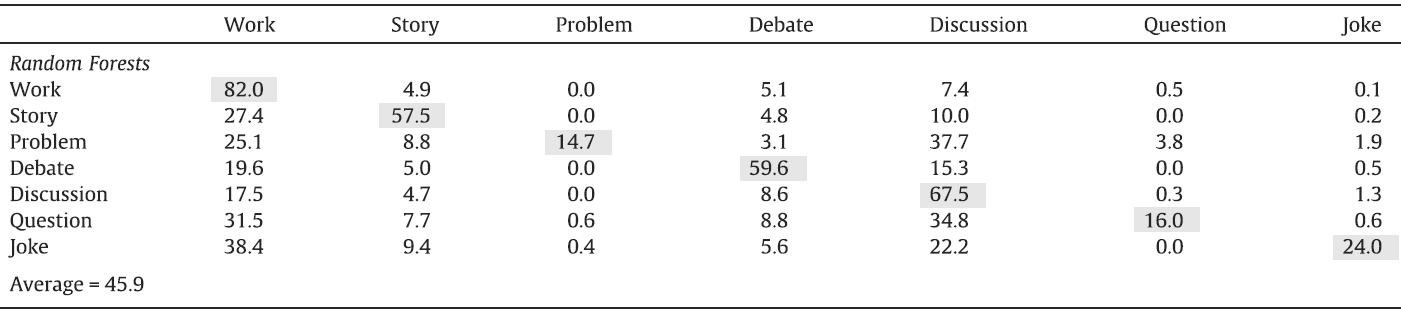 |
| The confusion matrix of Random Forests classification using visual words descriptor. |
Example results - Random Forests classification using visual topics
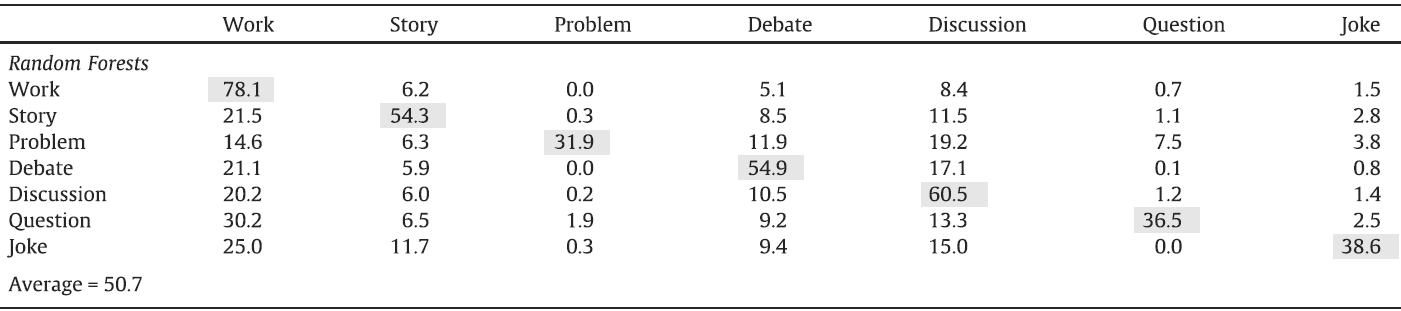 |
| The confusion matrix of Random Forests classification using visual topics descriptor. |
Publications
- J. Deng, X. Xie, and B. Daubney, A bag of words approach to subject specific 3D human pose interaction classification with random decision forests, Graphical Models, accepted, 2013.
- J. Deng, X. Xie, and B. Daubney, A Bag of Words Approach to 3D Human Pose Interaction Classification with Random Decision Forests, In Proceedings of the Computational Visual Media Conference, September 2013.
