CONVERSE is a human interaction recognition dataset intended for the exploration of classifying naturally executed conversational scenarios between a pair of individuals via the use of pose- and appearance-based features. A in-depth survey of the current state of publicly available datasets to the action recognition community highlights several key layers in human action, from single person actions to multi-person interactions. Current depth-based datasets describe actions or interactions in which classes are often represented by a series of key poses which are readily identified in depth-based representations (i.e. kicks and punches). The motivation behind CONVERSE is to present the problem of classifying subtle and complex behaviours between participants with pose-based information, classes which are not easily defined by the poses they contain. A pair of individuals are recorded performing natural dialogues across 7 different conversational scenarios by use of commercial depth sensor, providing pose-based representation of the interactions in the form of the extracted human skeletal models. Baseline classfication results are presented in the associated publication to allow cross-comparison with future research into pose-based interaction recognition.
We hope that the challenging problem CONVERSE presents can help further understanding of human interactions and pattern recognition techniques in the field of pose-based human action recognition on complex classes. The CONVERSE dataset and survey of the current key public datasets are presented in the paper “From pose to activity: Surveying datasets and introducing converse“. For further information please contact us.
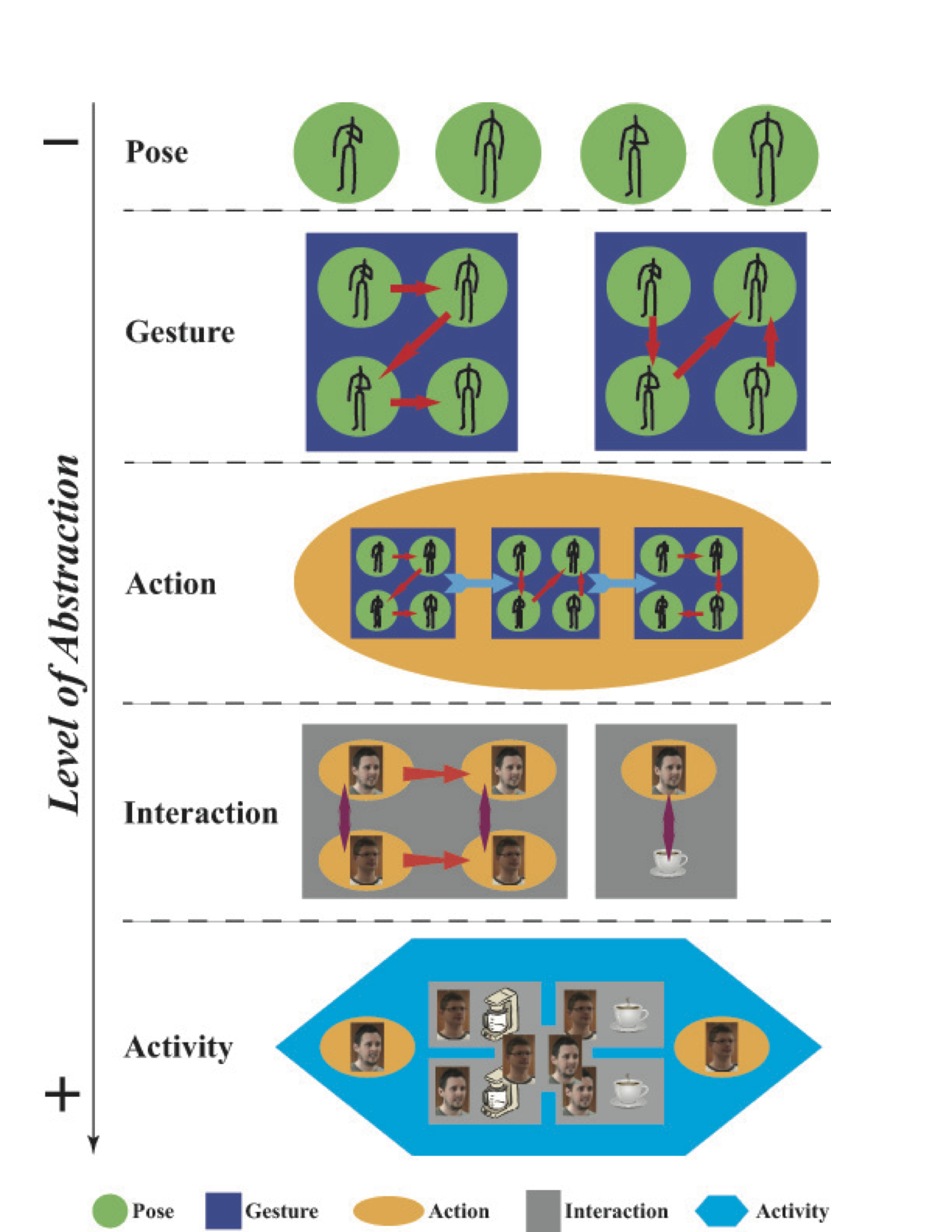
Key levels of abstraction identified within the current human action recognition datasets. CONVERSE resides within the person-to-person interaction layer and provides pose based representation of subtle classes that are not defined by pose.
The full version of the CONVERSE publication can be found within the 2016 CVIU special issue on Individual and Group Activities in Video Event Analysis. For further details regarding the dataset and it's usage please refer to:
A summarized pre-print version of the CONVERSE publication is provided as an arXiv article found at http://arxiv.org/abs/1511.05788
@ARTICLE{converse2016,
author={Edwards, M. and Deng, J. and Xie, X.},
title={From pose to activity: Surveying datasets and introducing {CONVERSE}},
journal={Computer Vision and Image Understanding},
year={2016},
pages={73 - 105},
doi={http://dx.doi.org/10.1016/j.cviu.2015.10.010},
month={March},
volume={144},
issn={1077-3142},
note={Special Issue on Individual and Group Activities in Video Event Analysis}
}
CONVERSE is comprised of 7 conversational interaction tasks between 16 subjects, separated into 8 pairwise interactions. Overall the total CONVERSE dataset consists of 482 minutes, containing 869,142 pose frames and 724,285 RGB face frames. The provided classes provided are: (1) Describing Work, (2) Story Telling, (3) Debate, (4) Discussion, (5) Telling Jokes, (6) Problem Solving and (7) Subjective Question.
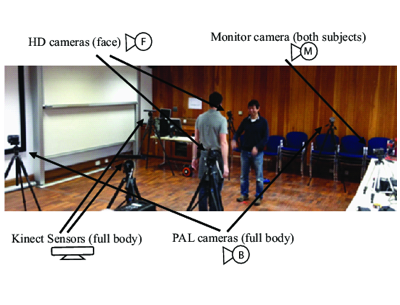
Participants were located within a boardroom containing a static cluttered background. Subjects were loosely positioned 1 metre apart, however their movements were not restricted. The full body of each participant was captured by a Microsoft Kinect sensor recording at 30fps. The face of each participant was recorded using a single HD camera recording at 25fps, with a second camera recording the full body appearance data at 25fps. All recordings are taken from in front of the participant, with horizontal offset to avoid occlusions from the other participant during the interaction. The Kinect and face camera are placed to the participant's front left', while the full body camera is placed to the front right. The apparatus layout, and examples of both appearance and skeleton recordings for each scenario are provided below.
Please note that the audio has been stripped from all recordings; this is due to the private nature of the dialogue present during the interactions, and the desire to ensure that all scenarios captured were unscripted and natural. For further information on the CONVERSE dataset, cross-validation parameters, and baseline results, please see the associated paper.
Table 1: Class descriptions for the CONVERSE dataset
Task
Description
Prepared in advance
Describing Work
Each participant describes their current work or project to partner. The partner then repeats the description back, to confirm they had understood.
Yes
Story Telling
Participant were asked to think of an interesting story they could tell their partner.
Yes
Debate
Participants prepared arguments for a given point of view, pro or con, on the topic “Should University education be free?”, and then debated this between them.
Yes
Discussion
Participants were asked to jointly discuss issues surrounding the statement “Social Networks have made the world a better place”, and come to agreement whether they believe the statement is true or not.
No
Telling Jokes
Participants were asked to take it in turn telling three separate jokes.
Yes
Problem Solving
Participants were given the problem “Do candles burn in space and if so what shape and direction?”, and asked to think of the solution of together.
No
Subjective Question
Participants responded to the subjective question “If you could be any animal, what animal and why?”
Each CONVERSE sequence is provided in two parts, the *.knt files and *.mat files. The KNT file stores 3D locations of each of the 20 joints of the kinematic model for each frame, and their associated tracking confidence, captured using Microsoft Kinect for Windows with SDK Version 1.8. The MAT file stores the frame number and the corresponding skeleton ID, which is used for synchronisation purpose.
KNTs follow the naming convention 'G*P*.knt', with G indicating a specific pairwise group and P indicating Person 1 and Person 2 in a given pairing. Synchronisation MAT files follow a similar naming convention of 'LUTG*P*.knt', corresponding to their respective KNT file.
The Matlab codes provides an interface to read the kinematic data of CONVERSE. The Matlab script DemoViewSkel.m demonstrates how to use the function to load the full dataset, select specified sequences, and visualise them. Please refer to the readme.md file and the comments within each function or script for specification details.
Although the appearance data for both the full body and face was collected during the recordings, the size of these files make it prohibitive to provide them online. If you require the appearance based data of the CONVERSE dataset then please contact us to arrange a transfer.
Please login using your account to download the data and code. If you require an account, please sign up here.